Patients often tell a lot more in conversations with medical professionals than is reflected in the official reports. The "close mining" of doctor-patient conversations can therefore bring up additional valuable information. Information that may not have been found relevant at the time of reporting and that only became meaningful later on.
But verbatim transcribing such conversations is a time-consuming and therefore costly operation that is often omitted.
With the advent of ever better Automatic Speech Recognition (ASR), it is possible to transcribe such conversations with increasing accuracy. As a result, information mentioned in the conversation but not "reported" can be extracted from oblivion and included in the patient dossier.
Moreover, in addition to the spoken facts (what was said), the way in which they were told (how it was said) may give relevance as well to the recorded conversations. Hesitations, pitch and loudness changes, long / short pauses; they all may give additional context to a conversation.
In order to be able to use these disclosure possibilities (what & how) it is necessary that :
- The transcription of the conversation is sufficiently accurate
- The recorded audio signal can be analysed in combination with grammatical entities
(i.e. pauzes before a negative noun) - There is a permanent link from the words to the recordings so that the main source can always be traced back when necessary
Transcription
ASR of well-recorded, not too specialised conversations is nowadays sufficiently good to be able to determine what was said. However, in doctor-patient conversations this is not always the case due to the very domain-specific words and expressions often used. Words which cannot yet be recognised by common ASR-engines.
Typical doctor-patient conversations and conversations about the "medical issues" contain words for medical conditions, names of medications and therapies, and other medical jargon words.
In a standard Dutch-Language Model (Dutch-LM), these words do simply not occur and as a result they cannot be recognized by the ASR-engine.
An example of a farma-medical OOV-word can be found in the transcription of a Radio 1 Broadcast in the MediaSuite.
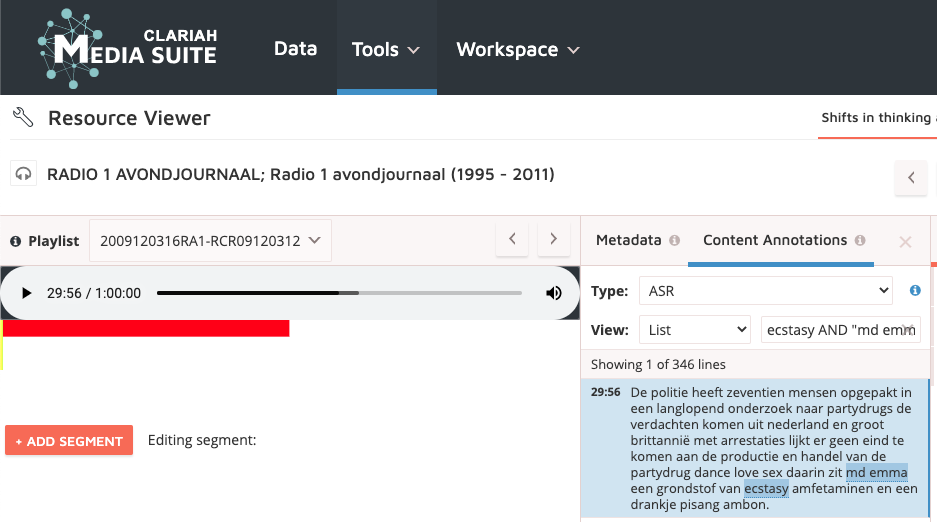 The recognition is quite good and words like ecstacy and amfitaminen are well recognised.
The recognition is quite good and words like ecstacy and amfitaminen are well recognised.
However, MDMA is mis-recognised as MD Emma. MDMA was not available in the wordlist and is an OOV-word.
LM-adaptation
By feeding a standard Dutch-LM with sufficient amounts of reports and transcripts of doctor-patient conversations, and with other textual material that resembles the conversations to be recognized, a new Language Model can be created that may increase the accuracy of the automatically created transcriptions of the "medical interviews".
This LM-adaptation can be seen as the main goal of the Homo Medicinalis Project.
Semantic and Acoustic Analysis
Once the ASR-transcription accuracies are sufficiently good, the other goals are in reach: retrieving, unlocking, and semantically and acoustically analyzing doctor-patient conversations.
Leveled approach

Schematic view of the leveled approach for the analysis of structures and unstructured AV-data, its embedding in the Media Suite, and the possible directions for future applications. In the leveled approach, three different levels are defined: from distant reading on the macro level to close reading on the micro level. This approach traces and analyses relevant empirical material in the digitized datasets. Crucially; scholars keep navigating between the research levels (close listening - distant reading), thus treating the search results as signposts to indicate the most relevant material in need of close reading/listening.
See, for an extensive explication and application of the levelled approach:
https://dspace.library.uu.nl/handle/1874/385019