Fine-tuning a general-purpose automatic speech recognizer (ASR) for Dutch with medical consultations on the use of pharmaceuticals
|
I am Cristian Tejedor García, from Valladolid, Spain. I am pleased to introduce myself as one of the researchers in the HoMed project. I will explain how I expect my academic profile, background and experience to connect to my research activities within HoMed. I received the B.Sc. and M.Sc. (Hons.) degrees in Computer Engineering and the Ph.D. (Cum Laude, international mention) in Computer Science from the University of Valladolid, Valladolid, Spain, in 2014, 2016, and 2020, respectively. I am currently a postdoctoral researcher in speech technology at Centre for Language and Speech Technology, (CLST, Radboud University Nijmegen, The Netherlands) and an honorary collaborator of the ECA-SIMM Research Group (University of Valladolid). |
 |
Research Interests
My research interests and experience span a wide range of topics in pronunciation training with speech technologies from advanced software development with the Kaldi speech recognition environment, to the analysis and design of pronunciation learning applications and human–computer interaction. These interests are directly related to my thesis "Design and Evaluation of Mobile Computer-Assisted Pronunciation Training Tools for Second Language Learning".
Through the Ph.D. degree, my course work has covered a wide range of topics in Computer Science. My research in computer-assisted pronunciation training area has provided me with the opportunity to understand automatic speech recognition (ASR), speech synthesis and human-computer interaction by means of empirical research with real users. Since 2015, I published almost twenty papers in internationally reputable and indexed journals and conferences, such as IEEE Transactions on Learning Technologies journal (2020), IEEE Access journal (2020), InterSPEECH (2016), EDULEARN (2020) or SLATE (2017), among others. My publications can be found at http://orcid.org/0000-0001-5395-0438.
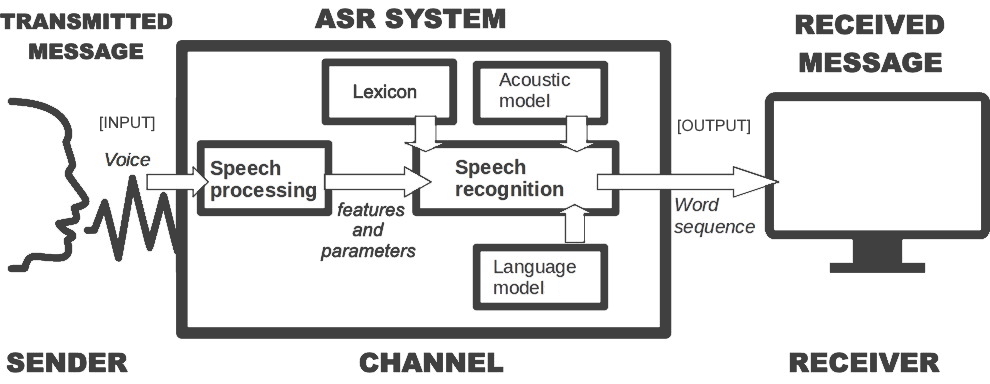
During my first months in HoMed project I have been finding my way with the general-purpose Dutch ASR system (Kaldi NL) and other webservices provided by CLST. Kaldi_NL is based on the Spoken Dutch Corpus (CGN) which contains Dutch recordings spoken by speakers (age range 18-65 years old) from all over the Netherlands and Flanders. The total amount of training material is 483 hours, spoken by 1185 female and 1678 male speakers. This system will be the baseline for the fine-tune ASR for HoMed, so that we will improve the current models by adapting them to the health topic.
As you might know, ASR is a technology that converts speech to text in real time. Essentially, we can use ASR to identify and verify the identity of the speakers, and as a second step, we can use natural language understanding to determine what their intentions are. We could also combine ASR with other technologies, such as a chat-bots or text-to-speech to try to keep a conversation with the speaker. Although real-time analysis of the speech data is not trivial, in the nearby future we will be able to assist advisors with very accurate automated translation and emotion detection of the speech. You can find state-of-the-art ASR technology in virtual assistants at home or in dictations systems.
How ASR works
You might wonder how ASR works. Imagine you have a speech signal that is digitized or you have several digital speech recordings on your computer. The first step that you have to do is you make a time window over 25 or 30 milliseconds to calculate the speech features and then you move the window at 10 milliseconds. You repeat this process again and again. That is the way that you process the digital speech into small parts, as up to three times overlap, and you calculate the features there that results in a set of phonemes. Basically, an acoustic model is a set of most probably phonemes. For instance, if you use Dutch acoustic models with the parameters that they are built on, a set of phonemes and the correct text output, that means that you have each window with an estimation of the most likely phonemes that are set.
Language Model
The next important part of ASR is the language model. It predicts (the most likely) words given to three or four words before with a statistical model. So, depending on the context and depending on the language model the ASR outcome can be different. There is a difference between the way we write and we are speaking so ideally speaking we need a lot of transcriptions from actual conversations and we need to make a transcription and use the transcription as a language model. However it costs a lot of money and it is a lot of work to collect enough data, so to help the system we are collecting audio/video material related to pharmaceuticals to add that to the transcriptions to build the language model. We also need a lexicon, that is, a list of non-repeated words included in the language model with their phonetic transcriptions.
In health environment we speak a little bit different since we use other words related to medicines, doctors, illnesses, etc. So, in a health language model we need to include the medicine and pharmaceutical words. You can do that by adding to the language model a lot of text from transcriptions from book, newspapers or videos which talk about health issues. So, you change your existing standard language model into a health language model (you could apply this process to other areas, such as the Dutch Police or Nederlandsche Bank). In summary, to create a health language model, you add different texts which are spoken about a certain small topic (health) and add them to the standard language model.
Training
The training data must be constantly updated. For example, you will not obtain good results with contemporary Dutch speech using an ASR trained on speech data of the 80s. Also ASR struggles with the large variation in speech due to age, gender, speech impairment, race, and accents. That is the reason why you must fine-tune your ASR to the specific context of application. In HoMed, +200 hours of real-life recordings (video/audio) of medical visits with patients with either Chronic obstructive pulmonary disease (COPD) or cancer, and patient visits to the pharmacists will be added as training data. Part of this data will be transcribed at Nivel, since it is very sensitive data.
All in all, you have your specific speech data as input, you do the feature extraction and calculate the features, you try to get the most likely phonemes and you put all that information inside a search algorithm. This algorithm uses the language model and also a lexicon, so that there are words which are possible recognizable and the combination of (1) lexicon and the (2) language model and (3) phonetic representation gives you an hypothesis of the text you can recognize and the first hypothesis is the text you show as output. However, when you generate your hypothesis you may notice some errors: some particular words are not included in the lexicon or even in the language model. In this case you must retrain your models with this new information and process the same phrases and then you hope that those particular words will be recognized as good as the other words. So, it is a constant updating of your language model by generating the hypothesis asking people if they can control the outcome if it is okay it is okay if not they will change the outcome and that text is sent to the lexicon and language model and then the language model is retrained this the corrected text.
Performance of the results
In the recent years by the use of deep neural nets or artificial intelligence we see that under optimal condition ASR is almost as good as that of humans. For instance, if you record some utterances and ask people to provide the verbatim transcription there might be some mistakes. In particular, the human rate accuracy is 95% when transcribing manually speech data. A good ASR system perfomance should be close to that percentage.
We can calculate the performance of an ASR system with the metric Word Error Rate (WER). It is the number of errors divided by the total words. That is, the number of substitutions, deletions and insertions factored by the total amount of words. So, the higher the value, the worse the performance. If we have speech data of quiet conversations in a noise-free surrounding by native speakers who really speak in a grammatically correct way then the WER value could be 5%. This value will be worse if we are using daily conversations with some dialect and accents in a normal environment (with some background noise). Finally if we have telephony conversations with dialects and heavy accents by non-native speakers in a noisy environment, the final performance will be the worst possible. So WER heavily depends on the quality of the input speech.
Conclusion
To conclude, in HoMed I am part of a multidisciplinary team with a lot of expertise and experience with ASR and data preparation, which means I will be able to develop new skills from different areas. I will work closely with the other postdoctoral social scientist in the project, Berrie, who is an expert in media studies and data visualization. I will be responsible for not only the language and acoustic modeling of the ASR work within the project, but I also intend to learn the basics of visualization techniques of the pharmaceutical data.
This is my first post for the blog and I hope you find it useful. I expect we can start obtaining results as soon as possible. Please, do not hesitate to contact me if you have any question or concern.
Cristian
Contact:
